
![]() About two weeks ago I attended the Strata + HADOOP world conference, February 2015, in San Jose. I think the most notable observation from an IT perspective is that people are getting serious about it. The second is that the technology driving the HADOOP ecosystem is evolving at warp speed.
About two weeks ago I attended the Strata + HADOOP world conference, February 2015, in San Jose. I think the most notable observation from an IT perspective is that people are getting serious about it. The second is that the technology driving the HADOOP ecosystem is evolving at warp speed.
ClickToTweet: Security in the Data Lake from Strata + Hadoop @AshvinKamaraju #DefenderOfData http://bit.ly/1FZjgkm
One example for security - Cloudera now says that “Security is Foundational” and the new default. Cloudera also said that they created a data governance partnership with Intel and Master Card. Items addressed included HDFS encryption zones, key management, Sentry unified authorization, data governance and authentication. I’ve observed that the Cloudera distribution is addressing new security needs with every release, and this continues that trend. Another example – a session hosted by the security architect at VISA that I attended, where he definitely recommended using encryption in production deployments.
With this level of emphasis on security at the platform level, as well as additional application related controls that can be applied, such as field encryption or tokenization, the environment is making progress toward overcoming the security and compliance risks that customers must address in order to harness the value of all of the data from multiple sources.
The conference, organized by O-Reilly and Cloudera, has grown significantly in size this year and was hosted at the San Jose convention center for the first time. I was told that it was a sold out conference, and my additional observation was that all the sessions were definitely buzzing. The expo hall was huge and packed as well and I would say there were at least 100+ exhibitors. Microsoft and MapR were the primary sponsor, and attendees were primarily technical; technologists, engineers, data scientists, Big Data practitioners. Most sessions were a match for this audience as they were technical in nature.
Walking away from this conference I would definitely say HADOOP and its ecosystem is “Big Data” and forms the Enterprise Data Lake. Everything else just fits or flows into this ecosystem. An informal poll in talking to the attendees leads me to believe that HADOOP is most definitely beginning to get deployed in production across virtually every industry segment - but most notably in the financial/banking, healthcare, retail and telco/media verticals.
The pace of innovation in the HADOOP ecosystem is happening at warp speed. Real time analytics were a very hot topic. The hot item around this topic at this conference was a new compute engine called “Spark”, the hottest project at Apache and a potential replacement for Map Reduce. Databricks, a company in SF, is commercializing the technology and is perceived as the hottest new data company. The claim to fame for Spark is that it is a single compute engine that provides screamingly fast real time analytics and offers very simple APIs and programming paradigms (languages called Scala, R) that makes it very easy for application developers. A scientist from Databricks claimed that whereas time to sort 100tbytes with Map Reduce took 2000 machines about 72 minutes, SPARK could complete the sort using only207 machines in about 23 minutes. Predictions are that Map Reduce will be obsolete and Spark will be the new engine soon. Besides, SPARK, the other hot topics were machine learning and data visualization.
Of the HADOOP distributions, Cloudera and Hortonworks seem to have the most market share. However, MapR definitely seems to be garnering a lot of attention. They sponsored this conference, claimed they are the most deployed distribution in production, have many enterprise class features (replications, snapshots, mirroring etc.) etc. They also seem to be investing in a lot of Open Source Apache projects (Mesos, Drill etc.) that have a great deal of customer and community buy in.
It was also very heartening to get an update from DJ. Patil, the newly appointed Data Scientist for the Federal Government. Our fearless leader, President Obama, introduced DJ in a video clip, called Data Science a team sport and underscored the importance of Big Data. I learned that a number of government data sets have been released to the public to spur innovation and research. DJ claimed Obama is the most data driven U.S. President, pointing to the executive order he's issued to ensure that open and machine-readable data is the new government default policy.
[caption id="attachment_2031" align="aligncenter" width="730"]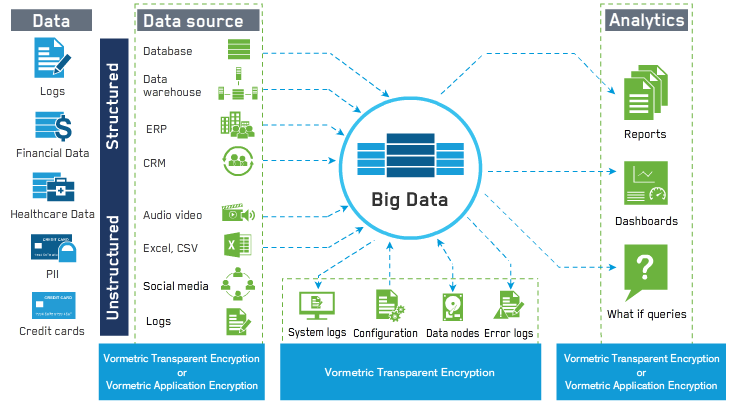 Vormetric Solutions Protect Data-at-rest Within Big Data Environments[/caption]
Vormetric Solutions Protect Data-at-rest Within Big Data Environments[/caption]
Be sure to check out data.gov which hosts 135000 data sets and executive order to ensure that open and machine-readable data is the new government default policy whitehouse.gov/usds (US Digital Service)
To wrap up, the pace of innovation and the value that the HADOOP ecosystem is bringing to the commercial world was definitely palpable. I also asked some questions at a panel discussion of some data scientists/professional services folks from a small company called “Silicon Valley Data Scientists”. They said the adoption of HADOOP is real and happening across a number of industry segments. However, the “Data Lake” vision is not yet realized due to political and organizational boundaries. As scientists, they said the Data Lake will derive the maximum value from data (from all sources and from all the Lines of Businesses) and they are evangelizing the Enterprise Data Lake with all their clients. With the Data Lake comes the need for security, especially the need to zone the data and provide visibility on an as needed or authorized basis.