
Recently we’ve been considering the topic of client licensing for systems based on the “software agent” model. A software agent is an application deployed onto multiple systems, which often depends on a central service for reporting diagnostics or accessing some resource. A simple example might be an anti-virus product installed throughout a business, which communicates with a central system to update virus definitions.
Some Thales products are based on a software agent model and we sell licenses to customers depending upon how many installations they plan to make. Historically this has been a simple process to manage, as customers rarely scaled their systems overnight and there was plenty of planning time to allow for license purchase and installation. But in recent years, cloud computing has altered that dynamic and now customers might not even know how many servers they have installed; they scale dynamically to cope with demand.
Our approach to licensing to date has been based on an honour system. We trust our customers want to pay us fairly for what they consume and tend to discuss their roadmap of expansion during regular account meetings. Unfortunately, this roadmap approach is no longer fit for purpose, since our customers need to rapidly react to their own customer demands without worrying about violating license agreements.
With this context in mind, we decided to research existing license technology and find a new route forward.
The Licensing Arms Race
It quickly became clear existing licensing technology wasn’t compatible with our honour system ethos. Most solutions assume the end customer is an adversary who wishes to violate their license terms by copying existing software from one machine to another. This is prevented by building a fingerprint for each server based on a combination of physical characteristics, such as processor speed, amount of RAM installed and hard-drive serial number. If the software is moved to another system, this is detected and the software will not run.
This approach did not appeal for two reasons: firstly, we don’t want to waste time (and money) fighting an adversary that doesn’t exist – we trust our customers; secondly, the technology is challenged by cloud environments, where cloning and snapshotting can produce multiple servers that appear identical by every measurable metric.
As a result of this research, we decided to design a different approach that could meet three criteria:
- It should be lightweight. No need to over-complicate something given we are not trying to be resilient against malicious users.
- Customers should be able to scale their use of the software without contacting us to obtain license files (or similar). Retrospective billing based on usage would be ideal.
- The system must be accurate in cloud environments, where server cloning is commonplace.
Our solution – ephemeral random fingerprints
The eventual solution came from considering the challenge of cloning. A cloned machine begins life in exactly the same state as its twin, which makes it impossible to distinguish between them. Any existing license files or data on the clone are identical, so the central system it talks to will struggle to differentiate between the two machines. In some situations, network addressing could help, but that is a brittle approach that can be undone by gateways, network address translation, and so on.
The Eureka moment came when we considered that a clone very quickly becomes a unique system based on the work that it does and the natural entropy in the environment.
We exploit this fact by creating short-lived (ephemeral) identities based on randomly generated numbers. A server is then identified by its entire history of ephemeral identities, joined in a chain. Each time the server contacts the central service, it sends the last N entries of the chain to identify itself. N can be adjusted to reduce the risk of message loss breaking the chain. N=2 is the minimum, but N=4 might be more resilient.
The ephemeral identity is refreshed on a regular basis, perhaps every ten seconds or five messages. The exact choice can be tailored to the scenario. But to avoid breaking the chain the identity should not be refreshed unless there is a message to send to the central service.
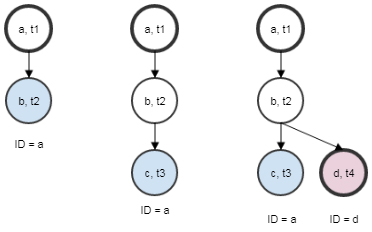
The diagram above shows how this works in practice. At time t3, we have only one server identified by the chain [a,b,c]. However, shortly later at time t4, we receive a message containing the chain [a,b,d]. This suggests a machine was cloned at some point between time t2 and t4. The central system can recognise this as a new server and will begin to track it accordingly.
The resulting data structure forms a directed acyclic graph (DAG) in which each sink represents a unique client. A source with more than one sink has been cloned at some point during its lifetime. If this data is stored in a sensible manner, computing operations on it are fast and efficient.
To produce billing data based on this graph, one can calculate the number of operations per unique client in a given time frame. An example of this calculation is shown in our prototype code (linked below).
How random is random?
The success of this system depends upon how quickly a clone diverges from its twin. Previous work by Everspaugh et al1 suggests cloned systems produce different results from their random number pools very quickly after booting. While their work focussed on proving when those random numbers were cryptographically strong enough, for our purposes it sufficed to have even one bit of difference between the next ephemeral identify generated by the clone and its twin.
We tested our example implementation using Amazon AWS and VirtualBox and were unable to clone a server without immediately producing different ephemeral identities. Going forward, this technology may make its way into our next generation of agent-based products.
A prototype implementation is available on our GitHub pages and a short paper describes the solution in a little more detail.
1Everspaugh, A., Zhai, Y., Jellinek, R., Ristenpart, T., Swift, M.: Not-so-random numbers in virtualized linux and the whirlwind rng. In: 2014 IEEE Symposium on Security and Privacy. pp. 559–574 (May 2014). https://doi.org/10.1109/SP.2014.42