
Bitslicing is a software implementation strategy for achieving constant time cryptographic algorithms to prevent cache and timing side-channel attacks. This blog post will give an overview of the technique and demonstrate a bitsliced implementation of AES encryption.

Software-based side channel attacks, such as cache-timing attacks, can be performed remotely without special privilege. This makes them practical threats for applications like cloud computing. An adversary can carry out such attacks by executing a spy process on a platform that is also executing the victim process. By measuring the timing of its own operations (or those of the victim process), it’s possible to extract sensitive information. For example, cache-timing attacks can effectively recover secret keys from cryptographic implementations such as AES [1,2] and RSA [3].
What About SGX?
The upcoming Intel SGX hardware extensions are also vulnerable to cache-timing attacks [2,3]. As mentioned in Intel's SGX Developer Manual, SGX is not designed to prevent side-channel attacks and it is up to the software developers to build side-channel resistant enclaves. As a hardware countermeasure to side-channel attacks, Intel provides AES-NI instruction set to improve on the AES algorithm and accelerates the encryption of data in the Intel® Xeon® processor family and the Intel® Core™ processor family. Apparently, this kind of hardware countermeasure completely relies on the trust of Intel hardware and cannot be available on every platform.
How it Works
Bitslicing techniques produce dedicated constant-time software implementations which resist cache-timing-attacks. It was originally proposed by Biham to improve DES performance [4]. Using the bitslicing technique, an algorithm is represented as a sequence of bit-logical instructions whose running time is independent of the input values. What this means to AES is to compute the S-Box and other layers on-the-fly using Boolean operations instead of pre-computed lookup tables.
When operating on bits, representing a single byte using eight Boolean variables is obviously inefficient. The standard bitslicing technique collects equivalent bits from multiple independent AES blocks into a single register to allow parallel computation of these blocks at the cost of one. An efficient bitsliced implementation of AES is given in [5], which further exploits the internal parallelism of a single AES block. As a result, with 128-bit registers, one can compute eight 16-byte AES blocks in parallel. The bitslicing technique can achieve its best performance when there is sufficient parallelism, such as AES-GCM. Modes like CBC are inherently sequential, but one could compute 8 parallel independent CBC encryptions.
Below we shall describe how to convert an AES state into bitsliced format and how to perform AES operations, i.e., SubBytes, ShiftRows, MixColumns, AddRoundKey and KeySchedule, on the bitsliced representation.
-
Bitsliced representation of the AES state. AES operates on a 16-byte state, [a0,a1,…,a15], which is represented as a two-dimensional array:
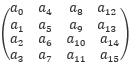
In the bitsliced representation, we collect the equivalent bits from the state and convert them into eight 16-bit integers, b0,b1,…,b7, where each bi contains the i-th bit of each ak in this order: [15 11 7 3 14 10 6 2 13 9 5 1 12 8 4 0]. In other words, the least significant bits of each byte are stored in b0 and the most significant bits are stored in the corresponding positions of b7. Similarly, using 32-bit integers, we can operate on two independent AES blocks in parallel by storing the sliced state of one block in the lower 16-bit and the other one in the higher 16-bit. Therefore, with processors that support 128-bit execution units, we can perform parallel computation on eight independent AES blocks.
- The SubBytes step. SubBytes step is a non-linear substitution step which transforms each byte ak in an AES state into another byte according to an 8-bit substitution box called S-Box. The S-Box substitution operation on the bitsliced state b0,b1,…,b7 can be computed using the gate logic operations given in Figure 5-9 in [6]. The Boolean circuit given in [6] is constructed using XOR, XNOR, and AND operations. The circuit is of depth 16 and contains 128 gates for the forward direction of S-Box and 127 gates for the reverse direction of S-Box.
-
The ShiftRows step. ShiftRows rotates each row of an AES state matrix left by 0,1,2,3 bytes, respectively,
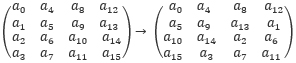
Correspondingly, the bits of each bitsliced state bi will be shifted according to the following pattern:
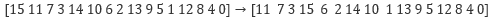
-
The MixColumns step. MixColumns multiplies a state matrix by a fixed matrix to obtain a new state matrix:
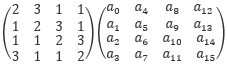
The eight bits of each entry are treated as coefficients of polynomial over GF(28 ). Multiplication is modulo an irreducible polynomial x8+x4+x3+x+1. Addition is XOR. For example, the least significant bit a0,0 of a0 is obtained as:

In bitsliced form, this corresponds to the ⊕ between the following rotated b0 and b7:

-
The AddRoundKey step. AddRoundKey combines the subkey with the AES state:
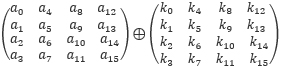
In bitsliced representation, each round key is also converted to a sliced form (s0,s1,s2,s3,s4,s5,s6,s7) and the corresponding AddRoundKey can be performed as:
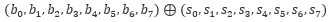
- AES Key Schedule. The key schedule computes a sequence of round keys from the initial key using rotations, XORs and SubBytes. These operations on bitsliced representation are already given above. After converting the initial key into bitsliced form, we can perform key schedule using above bitsliced implementation.
In Summary
Bitslicing uses only bit operations throughout the algorithm which eliminates all the secret-dependent memory access or branches. The execution time of such an algorithm does not depend on the secret inputs, therefore it provides truly constant time implementation to resist timing analysis. Many C programs can be converted into equivalent Boolean circuits using tools like [8,9]. However, representing an algorithm using Boolean functions inevitably introduces significant performance overhead. To achieve reasonable performance, bitslicing relies on the minimisation of gates used in Boolean circuits, a sufficient level of internal and external parallelism and sometimes hardware support (e.g., bitsliced Montgomery multiplication for RSA and ECC [7]).
Bibliography
[1] D. J. Bernstein, “Cache-timing attacks on AES,” Department of Mathematics, Statistics, and Computer Science, University of Illinois at Chicago, Tech. Rep., 2005.
[2] MemJam: A False Dependency Attack Against Constant-Time Crypto Implementations in SGX. CT-RSA 2018
[3] Michael Schwarz, Samuel Weiser, Daniel Gruss, Clémentine Maurice, Stefan Mangard. Malware Guard Extension: Using SGX to Conceal Cache Attacks. DIMVA 2017
[4] Eli Biham. A fast new des implementation in software. In Fast Software Encryption: 4th International Workshop, FSE’97, volume 1267 of LNCS, pages 260–272. Springer, 1997.
[5] Emilia Käsper and Peter Schwabe. 2009. Faster and Timing-Attack Resistant AES-GCM. In Proceedings of the 11th International Workshop on Cryptographic Hardware and Embedded Systems (CHES '09)
[6] Joan Boyar and Rene Peralta, A depth-16 circuit for the AES S-box. https://eprint.iacr.org/2011/332.pdf
[7] M. Sudhakar, R. V. Kamala, and M. Srinivas, “A bit-sliced, scalable and unified montgomery multiplier architecture for RSA and ECC,” in 2007 IFIP International Conference on Very Large Scale Integration, 2007, pp. 252–257.
[8] CBMC: Bounded Model Checking for Software. https://www.cprover.org/cbmc/
[9] A. Holzer, M. Franz, S. Katzenbeisser, and H. Veith. Secure two-party computations in ANSI C. In Proceedings of the 2012 ACM conference on Computer and communications security (CCS '12).