
 Ludmila Rinaudo | Product Management
Ludmila Rinaudo | Product Management
Given the pace of data growth and the complexity of hybrid IT environments, the discovery and classification of sensitive data is no simple task. In a recent study, IDC predicted the global datasphere will more than double in size from 2022 to 2026, and that 80% of that data will be unstructured. Traditional approaches to data classification use manual tagging which is labor-intensive, error-prone, and not easily scalable. As organizations create more diverse and more user-focused data products and services, there is a growing need for Machine Learning (ML) to automate classification and improve the accuracy of results. This blog will explain how Thales is enhancing CipherTrust Data Discovery and Classification (DDC) with ML models that help analyze data, learn from insights, and improve results.
Navigating Diverse Data Repositories for Visibility
Data discovery is the first step for organizations looking to comply with data protection regulations worldwide. Part of this process includes identifying where and how data is stored—on-premises, in third-party servers or in the cloud. While an organization might already know the location of structured data such as a primary customer database store, unstructured data (such as that found in stray files and emails) is more difficult to locate. Once an organization’s data has been discovered it can be categorized across a variety of metrics—for example, according to the sensitivity of the data or ease of identification of individuals from the data—and classified depending on its relative risk. Data discovery and classification solutions, like CipherTrust Data Discovery and Classification (DDC), are software tools used by organizations to find and remediate Personally Identifiable Information (PII) and sensitive information across structured and unstructured data sets—whether stored across servers, on desktops, in emails and databases, on-premises or in the cloud.
Next-generation Data Discovery and Classification
Thales is extending CipherTrust Data Discovery and Classification (DDC) to use a combination of pattern matching with Machine Learning (ML) models to connect disparate data points into meaningful relationships. This means finding data wherever it is within an organization’s IT systems and layering in context for classification to enhance the efficiency and accuracy of results. ML builds on different types of models for different purposes, for example categorization to determine a document category or Named Entity Recognition (NER) to identify sensitive data across diverse locations.
1) Pattern Matching: The foundational classification method for data, this technique matches known patterns to information that lives in your data. CipherTrust DDC is powered by Ground Labs’® proprietary pattern-matching engine, Ground Labs Accurate Search Syntax (GLASS™), to scan all files in their entirety. CipherTrust DDC is pre-built with more than 250 infotypes (entities), covering the vast majority of regional and global data privacy laws and regulations. This includes personal data like email addresses, dates of birth, telephone numbers, and national ID numbers; financial data like bank account numbers and credit card numbers; and patient health data. CipherTrust DDC can also discover secrets—like AES keys, auth secrets, and SSH keys—to help catch security issues like hardcoded private keys (see the full list of infotypes supported by DDC here). In addition, CipherTrust DDC includes pre-built core classification profiles aligned with 17 major data laws and regulations including GDPR, PCI-DSS, CCPA, LGPD, and HIPAA. Beyond pattern matching, CipherTrust DDC, powered by GLASS, also uses checksums, function calls and other methods for data validation and to enable false positives to be discarded quickly.
2) Named Entity Recognition (NER) for infotypes (entities): NER is a Natural Language Processing (NLP) method that extracts ‘named entities’– such as names, locations, and dates—from unstructured text without requiring time-consuming human analysis. For example, date of birth is a named entity that can come in many different formats and can have a variety of descriptors in different languages. Traditional approaches to classification might use keywords like “DOB” and “fecha de nacimiento” to layer on context—but this is not easily scalable across different types of documents or global languages. Instead, CipherTrust DDC uses NER to find relationships between the entities to layer on context at scale. Figure 1 shows example scan results listing infotypes found along with the number of occurrences for each one.

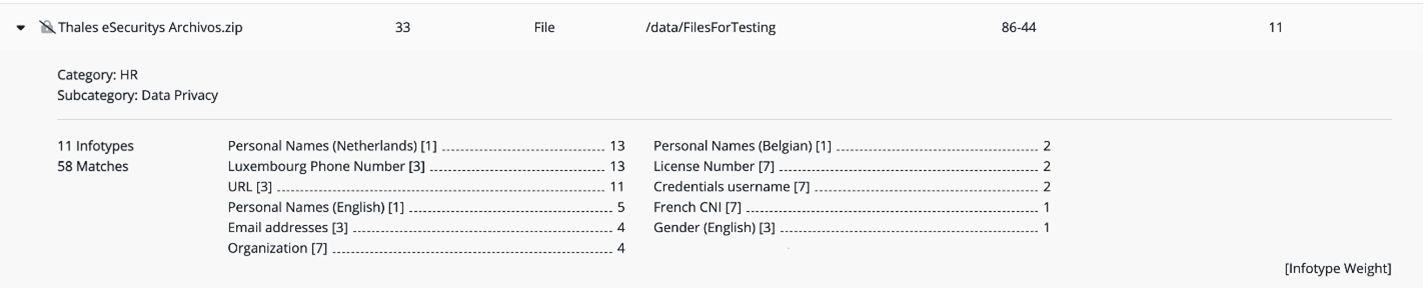
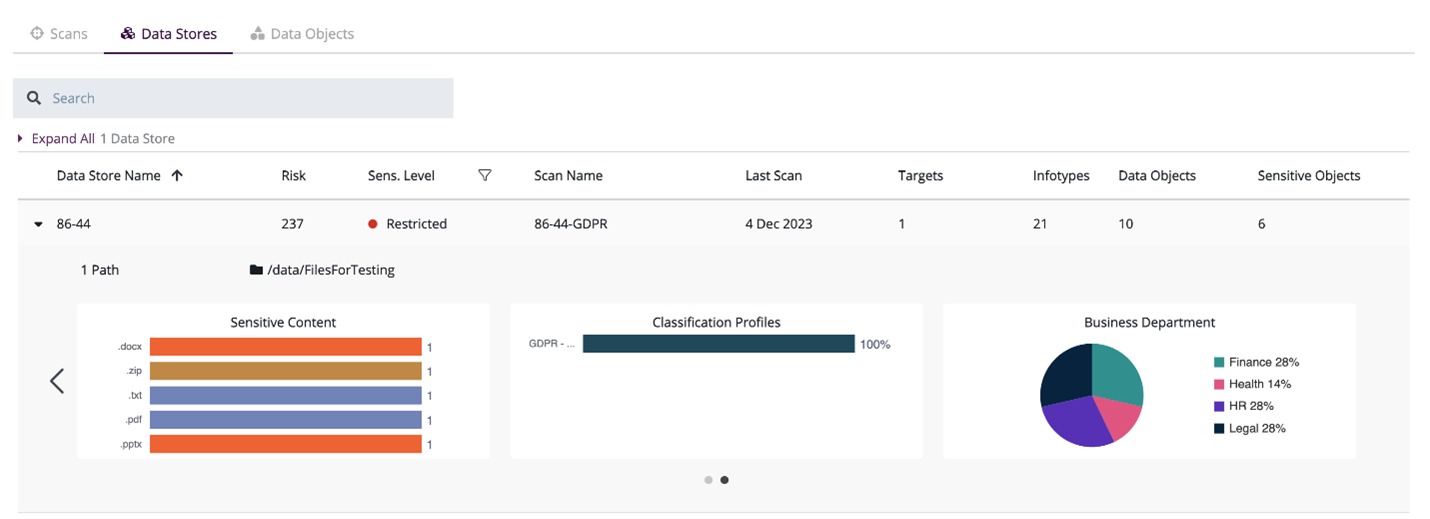
3) Machine Learning (ML) for Category Classification: Another ML model is used to determine the document category based on the content of the object—for example, a receipt or invoice would be classified as a financial document, which likely contains PII. CipherTrust DDC uses a ML model for category classification to identify with high probability whether a document is healthcare, finance, legal or HR related. Figure 2 shows the category distribution by business department for all documents in a selected data store.
Next Steps
Leveraging the right tools can help organizations accelerate their ability to classify data and adhere to compliance regulations. CipherTrust Data Discovery and Classification Machine Learning capabilities are currently in development. If you are interested in participating in the beta program, contact Thales to join the registration list.
Learn more about how Thales CipherTrust Data Discovery and Classification can bring agility and confidence to your data management.