
CipherTrust Tokenization
CipherTrust Tokenization reduce drásticamente el costo y el esfuerzo necesarios para cumplir con las políticas de seguridad y los mandatos normativos como PCI DSS, al mismo tiempo que simplifica la protección de otros datos confidenciales, incluida la información de identificación personal (PII). Si bien no existen estándares de tokenización en la industria, la mayoría de las soluciones de tokenización se dividen en una de dos arquitecturas: tokenización sin bóveda o con bóveda. Ambos protegen y anonimizan los activos confidenciales. El software de tokenización puede residir en el centro de datos, en entornos de Big Data o en la nube.

Si está buscando soluciones de tokenización, considere:
- CipherTrust Vaultless Tokenization con enmascaramiento dinámico de datos o
- CipherTrust Vaulted Tokenization
- Ambas ofertas son fáciles de usar, amigables con la nube y altamente seguras.
Aprenda cómo la tokenización puede ser una herramienta valiosa para ayudarlo a asegurar su transformación digital:

- Ventajas
- Características
- Especificaciones
Reduzca de manera eficiente el alcance del cumplimiento de PCI DSS
La tokenización puede eliminar los datos del titular de la tarjeta del alcance de PCI DSS con un costo y esfuerzo mínimos, lo que permite a las organizaciones ahorrar en los costos asociados con el cumplimiento del estándar de la industria.
Proteja convenientemente la información de identificación personal
Las arquitecturas de TI modernas requieren tanto el uso como la protección de la información de identificación personal (PII). Con la tokenización de CipherTrust, se obtiene la protección de la PII sin la administración de claves de cifrado requerida por el desarrollador de software.
Fomentar la innovación sin introducir riesgos
Tokenice datos y mantenga el control y el cumplimiento al mover datos a la nube o entornos de Big Data. Los proveedores de servicios en la nube no tienen acceso a las bóvedas de tokens ni a ninguna de las claves asociadas con la raíz de confianza de tokenización.
Arquitecto para sus requisitos: sin bóveda o con bóveda y compatible con la nube
Ambas soluciones de CipherTrust Manager se aprovechan como una fuente de clave de cifrado segura. Todo el software, compatible con la nube, está fácilmente disponible, incluso con la raíz de confianza FIPS 140-2 Nivel 3.
Opciones de tokenización
La tokenización sin bóveda o sin almacenamiento con enmascaramiento dinámico de datos ofrece preservación del formato o tokenización aleatoria para proteger los datos confidenciales. Una API RESTful en combinación con administración y servicios centralizados permite la tokenización con una sola línea de código por campo. El servicio es proporcionado por servidores de tokenización CipherTrust dedicados, con capacidad de clúster distribuido, que brindan una separación total de funciones. La gestión de la tokenización con flujos de trabajo de configuración convenientes se produce en una interfaz gráfica de usuario. La simplicidad resulta de la capacidad, con solo una línea de código insertada en las aplicaciones, para tokenizar o detokenizar con el enmascaramiento dinámico de datos.
- El enmascaramiento dinámico de datos se proporciona a través de administradores que establecen políticas para devolver un campo completo tokenizado o enmascarar dinámicamente partes de un campo en función del usuario o grupo, integrado con LDAP o AD. Por ejemplo, un equipo de seguridad podría establecer políticas para que un usuario con credenciales de representante de servicio al cliente solo reciba un número de tarjeta de crédito con los últimos cuatro dígitos visibles, mientras que un supervisor de servicio al cliente pueda acceder al número de tarjeta de crédito completo sin cifrar. ¿Busca enmascaramiento de datos estáticos? La tokenización ofrece enmascaramiento de datos estáticos, pero, para la amplia gama de casos de uso de enmascaramiento de datos estáticos, considere CipherTrust Batch Data Transformation.
- La tenencia múltiple se proporciona con grupos de tokenización, que garantizan que los datos tokenizados por un grupo no puedan ser destokenizados por otro y se administren de forma centralizada.
- Plantillas de tokenización centralizadas. En el centro de la simplicidad de programación de Vormetric Tokenization se encuentra la plantilla de tokenización.
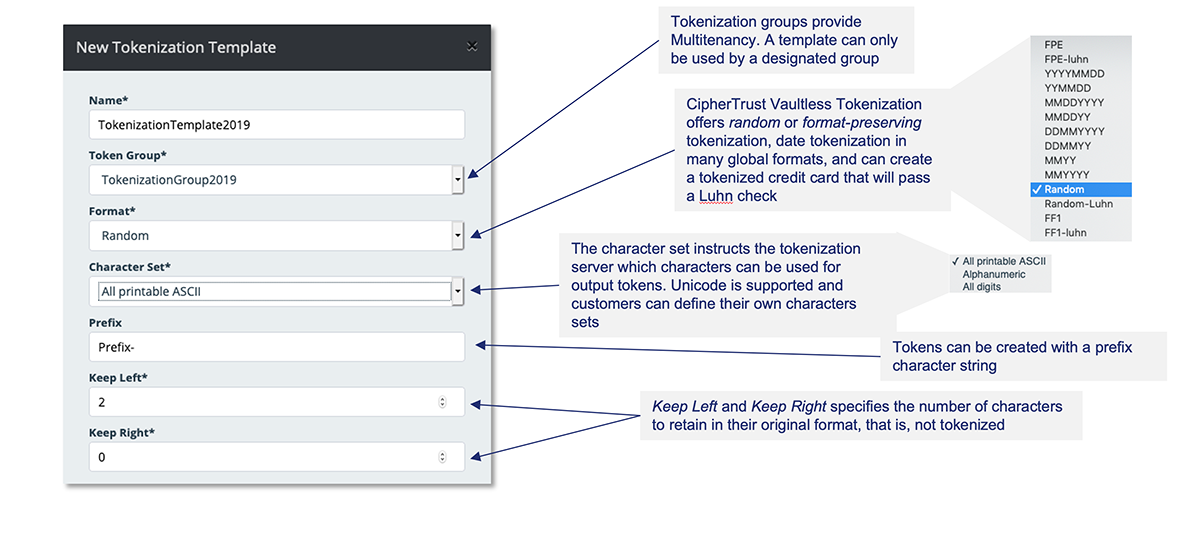
Tokenización con bóveda CipherTrust Vaulted Tokenization ofrece tokenización que conserva el formato sin interrupciones con una amplia gama de formatos existentes y la capacidad de definir formatos de tokenización personalizados. La tokenización de datos se puede aplicar directamente en los servidores de aplicaciones en los que está instalado el software, o las solicitudes de API de la aplicación a los servidores web en los que está instalado el software de tokenización se pueden utilizar para la tokenización. Se proporciona una gama completa de formatos de tokenización predefinidos con la distribución y los clientes pueden crear formatos adicionales.
Tokenization sin bóveda Especificaciones técnicas
Capacidades de tokenización
- Tokens de conservación de formato con opción irreversible. Tokenización aleatoria para una longitud de datos de hasta 128K. Fecha de tokenización. Opción de verificación de Luhn para FPE y tokens aleatorios
Capacidades de enmascaramiento de datos dinámicos
- Basado en políticas, número de caracteres izquierdos y/o derechos expuestos, con carácter de máscara personalizable
- Autenticación con Protocolo ligero de acceso a directorios (LDAP) o Active Directory (AD)
Factores de forma y opciones de implementación del servidor de tokenización
- Formato de virtualización abierto (.OVA) y Organización Internacional de Normalización (.iso)
- VHD de Microsoft Hyper-V
- Imagen de máquina de Amazon (.ami)
- Mercado de Microsoft Azure
- Google Cloud Platform
Requisitos de implementación del servidor de tokenización
- Hardware mínimo: 4 núcleos de CPU, 16 GB de RAM. Se recomienda 32 GB de RAM
- Disco mínimo: 85GB
Integración de aplicaciones
- API RESTful
Desempeño:
- Más de un millón de transacciones de tokenización del tamaño de una tarjeta de crédito por segundo, por servidor de tokens (usando múltiples subprocesos y modo por lotes [o vectorial]) en un servidor de 32 núcleos (Xeon E5-2630v3 de dos sockets) con 16 GB de RAM
Tokenización con bóveda Especificaciones técnicas
Capacidades de tokenización
- Tokens que preservan el formato
- Generación de tokens aleatoria o secuencial
- Enmascarada: últimos cuatro, primeros seis, primeros dos, etc.
- Enmascaramiento de longitud y amplitud fijadas
- Formatos personalizados definidos por el cliente
- Expresiones regulares (estilo Java)
Bases de datos almacenes de token compatible
- Microsoft SQL Server
- Oracle
- MySQL
- Cassandra
Integración de aplicaciones
- REPOSO
- Java
- .NET
Productos relacionados