
CipherTrust Tokenization
CipherTrust Tokenization réduit considérablement le coût et l’effort requis pour se conformer aux politiques de sécurité et aux mandats réglementaires tels que PCI DSS tout en simplifiant également la protection des autres données sensibles, y compris les données à caractère personnel. Bien qu’il n’existe aucun standard de tokénisation dans l’industrie, la plupart des solutions de tokénisation appartiennent à deux architectures : tokénisation avec ou sans coffre. Les deux protègent et anonymisent les ressources sensibles. Les logiciels de tokénisation peuvent résider dans le centre de données, les environnements de Big Data ou le cloud.

Si vous cherchez des solutions de tokénisation, envisagez :
- CipherTrust Vaultless Tokenization with Dynamic Data Masking ou
- CipherTrust Vaulted Tokenization
- Les deux offres sont faciles à utiliser, compatibles avec le cloud et hautement sécurisées.
Découvrez comment la tokénisation peut être un outil précieux pour aider à protéger votre transformation numérique :

- Avantages
- Fonctionnalités
- Caractéristiques
Réduire avec efficacité la portée de la conformité PCI DSS
La tokénisation peut retirer les données de propriétaire de carte de la portée PCI DSS avec un coût et des efforts minimaux, permettant aux organisations de réduire les coûts associés à la conformité au standard de l’industrie.
Protéger les informations d’identification personnelle en toute simplicité
Les architectures informatiques modernes nécessitent l’utilisation et la protection des informations d’identification personnelle. Avec CipherTrust Tokenization, la protection de ces données est obtenue sans que le développeur logiciel n’exige une gestion des clés de chiffrement.
Favoriser l’innovation sans introduire de risque
Tokénisez les données et conservez le contrôle et la conformité lors de la migration des données vers le cloud ou les environnements de Big Data. Les fournisseurs de cloud n’ont aucun accès aux coffres de tokens ou aux autres clés associées à la racine de confiance de la tokénisation.
Adapter l’architecture en fonction de vos exigences : avec ou sans coffre et compatible avec le cloud
Les deux solutions tirent parti de CipherTrust Manager en tant que source de clé de chiffrement sécurisée. Tous les logiciels compatibles avec le cloud sont facilement disponibles, avec une racine de confiance FIPS 140-2 niveau 3
Options de tokénisation
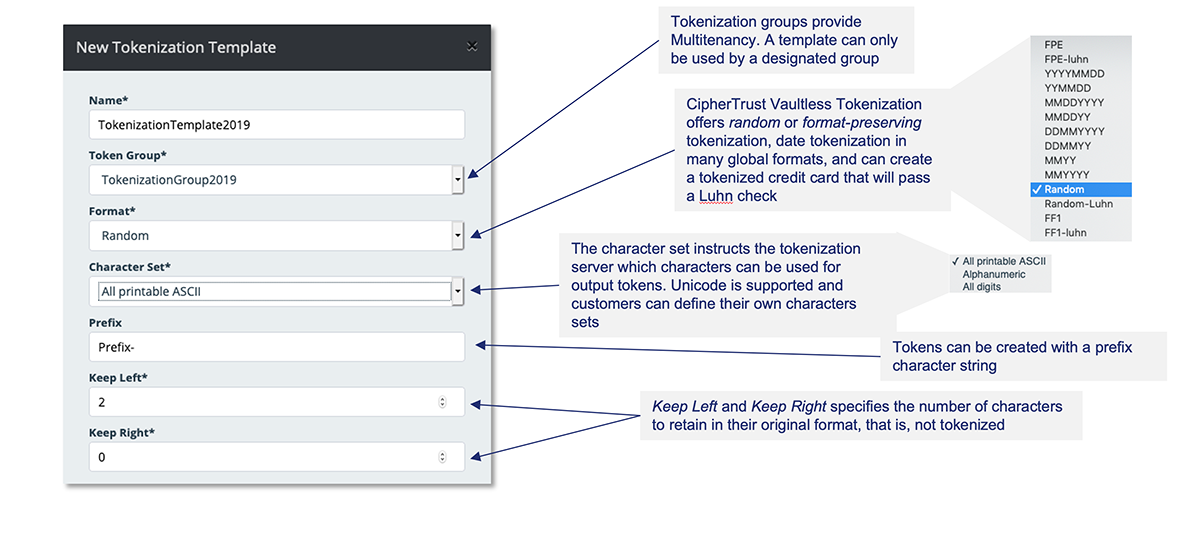
Vaultless Tokenization with Dynamic Data Masking offre une tokénisation préservant le format ou aléatoire pour protéger les données sensibles. Une API RESTful associée à la gestion centralisée et aux services permet la tokénisation avec une seule ligne de code par champ. Le service est fourni par des services CipherTrust Tokenization dédiés et en cluster distribué en fonctionnement, offrant une séparation des devoirs complète. La gestion de la tokénisation avec des processus de configuration pratiques a lieu dans une interface utilisateur graphique. La simplicité découle de la capacité de tokéniser ou de détokéniser avec masquage dynamique des données en insérant seulement une ligne de code dans les applications.
- Le masquage dynamique des données est fourni par le biais des administrateurs qui établissent des politiques afin de renvoyer un champ entier tokénisé ou de masquer de manière dynamique des parties d’un champ en fonction d’un utilisateur ou d’un groupe, intégré à LDAP ou AD. Par exemple, une équipe de sécurité pourrait établir des politiques de sorte qu’un utilisateur avec des identifiants de représentant du service client ne puisse recevoir qu’un numéro de carte de crédit où seuls les 4 derniers chiffres sont visibles, tandis qu’un superviseur du service client pourrait accéder en clair au numéro entier. Vous recherchez une solution de masquage statique des données ? Tokenization offre un masquage statique des données mais, pour la majorité des cas d’utilisation du masquage statique des données, envisagez CipherTrust Batch Data Transformation.
- La mutualisation est fournie avec des groupes de tokénisation, qui garantissent que les données tokénisées par un groupe ne peuvent pas être détokénisées par un autre et sont gérées de manière centralisée.
- Modèles de tokénisation centralisée La simplicité de programmation de Vormetric Tokenization est rendue possible par le modèle de tokénisation.
La tokénisation avec coffre CipherTrust Vaulted Tokenization offre une tokénisation préservant le format sans perturbations avec une vaste gamme de formats existants et la capacité de définir des formats de tokénisation personnalisés. La tokénisation des données peut s’appliquer directement sur les serveurs d’applications sur lesquels les logiciels sont installés, ou vous pouvez utiliser les demandes d’API des serveurs d’applications aux serveurs Web sur lesquels les logiciels sont installés pour la tokénisation. Une gamme complète de formats de tokénisation prédéfinis est fournie avec la distribution et les clients peuvent créer des formats supplémentaires.
Vaultless Tokenization : caractéristiques techniques
Fonctionnalités de Tokénisation
- Tokens préservant le format avec option irréversible. Tokénisation aléatoire pour des données d’une longueur pouvant atteindre 128 Ko. Tokénisation des dates. Option de validation de Luhn pour les tokens préservant le format et aléatoires
Capacités de masquage dynamique des données
- Basée sur les politiques, un certain nombre de caractères à gauche et/ou droite exposés, avec un caractère de masque personnalisable
- Authentification avec LDAP (Lightweight Directory Access Protocol) ou AD (Active Directory)
Facteurs de forme et options de déploiement du serveur de tokénisation
- Format Open Virtualization (.OVA) et International Organization for Standardization (.iso)
- Microsoft Hyper-V VHD
- Amazon Machine Image (.ami)
- Place de marché Microsoft Azure
- Google Cloud Platform
Exigences de déploiement du serveur de tokénisation
- Matériel minimum : 4 cœurs de processeurs, 16 Go de RAM (32 Go recommandé)
- Espace disque minimum : 85 Go
Intégration d’applications
- API RESTful
Performance :
- Plus d’un million de transactions de tokénisation de carte de crédit par seconde par serveur de token (utilisant plusieurs threads et le mode en bloc (ou vecteur)) sur un serveur à 32 cœurs (Xeon E5-2630v3 à deux sockets) avec 16 Go de RAM
Vaulted Tokenization : caractéristiques techniques
Fonctionnalités de tokénisation :
- Tokens préservant le format
- Génération aléatoire ou séquentielle de tokens
- Masqués : quatre derniers, six premiers, deux premiers, etc.
- Masquage fixe de la longueur et de la largeur
- Formats personnalisés définis par le client
- Expressions régulières (Style Java)
Bases de données de chambres fortes de tokens prises en charge
- Microsoft SQL Server
- Oracle
- MySQL
- Cassandra
Intégration d’applications
- REST
- Java
- .NET
Produits associés