
CipherTrust Tokenization
CipherTrust Tokenization dramatically reduces the cost and effort required to comply with security policies and regulatory mandates like PCI DSS while also making it simple to protect other sensitive data including personally identifiable information (PII). While there are no tokenization standards in the industry, most tokenization solutions fall into one of two architectures: vaultless- or vaulted tokenization Both secure and anonymize sensitive assets. Tokenization software can reside in the data center, big data environments or the cloud.

If you are seeking a tokenization solutions, consider:
- CipherTrust Vaultless Tokenization with Dynamic Data Masking or
- CipherTrust Vaulted Tokenization
- Both offerings are easy to use, cloud friendly, and highly secure.
Learn how tokenization can be a valuable tool to aid in securing your digital transformation:

- Benefits
- Features
- Specifications
Efficiently Reduce PCI DSS Compliance Scope
Tokenization can remove card holder data from PCI DSS scope with minimal cost and effort, enabling organizations to save on costs associated with compliance with the industry standard.
Conveniently Protect Personally Identifiable Information
Modern IT architectures require both use and protection of personally identifiable information (PII). With CipherTrust tokenization, PII protection is gained without encryption key management required by the software developer.
Foster Innovation Without Introducing Risk
Tokenize data and maintain control and compliance when moving data to the cloud or big data environments. Cloud providers have no access to token vaults or any of the keys associated with tokenization root of trust.
Architect for Your Requirements: Vaultless or Vaulted, and Cloud-Friendly
Both solutions leverage CipherTrust Manager as a secure encryption key source. All-software, cloud friendly, is readily available, including with FIPS 140-2 Level 3 Root of Trust.
Tokenization Choices
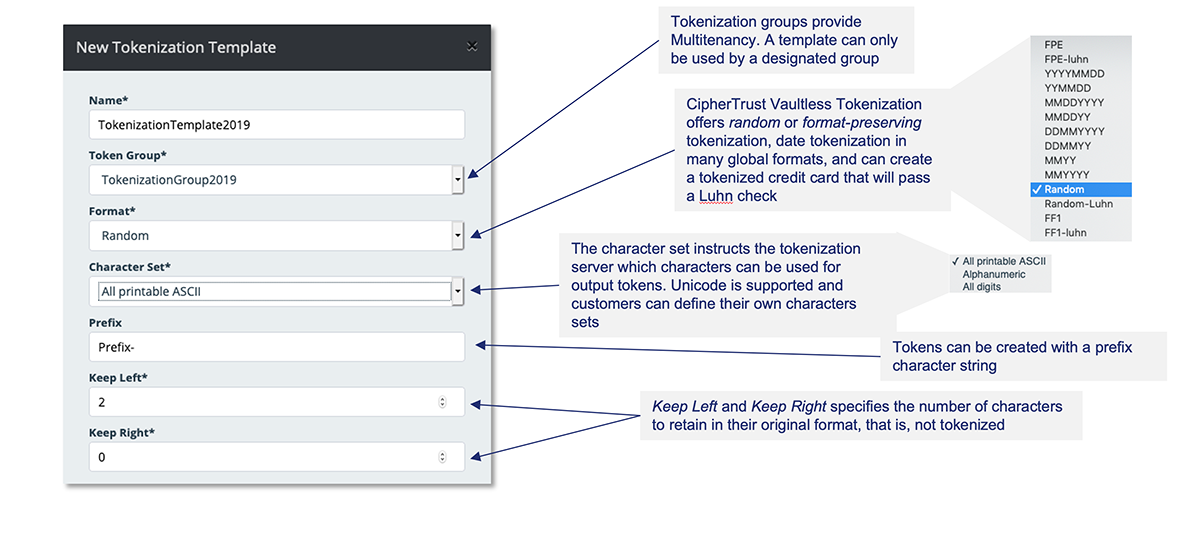
Vaultless Tokenization with Dynamic Data Masking offers format-preserving or random tokenization to protect sensitive data. A RESTful API in combination with centralized management and services enables tokenization with a single line of code per field. The service is provided by dedicated, distributed-cluster-capable CipherTrust Tokenization Servers, delivering full separation of duties. Tokenization management with convenient configuration workflows occurs in a graphical user interface. Simplicity results from the ability, with a few as just one line of code inserted into applications, to tokenize or detokenize with Dynamic Data Masking.
- Dynamic data masking is provided through administrators establishing policies to return an entire field tokenized or dynamically mask parts of a field based on user or group, integrated with LDAP or AD. For example, a security team could establish policies so that a user with customer service representative credentials would only receive a credit card number with the last four digits visible, while a customer service supervisor could access the full credit card number in the clear. Looking for static data masking? Tokenization offers static data masking, but, for the broad range of static data masking use cases, consider CipherTrust Batch Data Transformation.
- Multi-tenancy is provided with Tokenization groups, which ensure that data tokenized by one group cannot be detokenized by another and are centrally managed.
- Centralized Tokenization Templates. At the core of the programming simplicity of Vormetric Tokenization is the tokenization template.
Vaulted tokenization CipherTrust Vaulted Tokenization offers non-disruptive format-preserving tokenization with a wide range of existing formats and the ability to define custom tokenization formats. Data tokenization can be applied directly on application servers on which the software is installed, or API requests from application to web servers on which tokenization software is installed can be utilized for tokenization. A full range of predefined tokenization formats are provided with the distribution and customers can create additional formats.
Vaultless Tokenization Technical specifications
Tokenization capabilities
- Format-preserving tokens with irreversible option. Random tokenization for data length up to 128K. Date tokenization. Luhn checking option for FPE and random tokens
Dynamic data masking capabilities
- Policy based, number of left and/or right characters exposed, with customizable mask character
- Authentication with Lightweight Directory Access Protocol (LDAP) or Active Directory (AD)
Tokenization Server deployment form factors and options
- Open Virtualization Format (.OVA) and International Organization for Standardization (.iso)
- Microsoft Hyper-V VHD
- Amazon Machine Image (.ami)
- Microsoft Azure Marketplace
- Google Cloud Platform
Tokenization Server deployment requirements
- Minimum hardware: 4 CPU cores, 16 GB RAM. 32 GB RAM recommended
- Minimum disk: 85GB
Application integration
- RESTful APIs
Performance:
- More than 1 million credit card size tokenization transactions per second, per token server (using multiple threads and batch (or vector) mode) on a 32-core server (dual-socket Xeon E5-2630v3) with 16 GB RAM
Vaulted Tokenization Technical specifications
Tokenization capabilities:
- Format-preserving tokens
- Random or Sequential token generation
- Masked: Last four, First six, First two, etc.
- Fixed length and width masking
- Customer defined custom formats
- Regular expressions (Java style)
Supported Token Vault Databases
- Microsoft SQL Server
- Oracle
- MySQL
- Cassandra
Application integration
- REST
- Java
- .NET
Related Products